Welcome to the Wasteland: A Case Study in the Perils of Security Through Obscurity
Abstract
This page is a walkthrough for Vancouver, the first in a recent series of reverse engineering challenges from the embedded systems division at NCC Group.
Executive Summary
This system, reliant solely on security through obscurity, effectively grants arbitrary code execution to anyone who can understand the format for the debug payload.
Overview
First Working Exploit: 1225 UTC, October 29th, 2022Blockchain Timestamp: 1256 UTC, October 29th, 2022
Pastebin Timestamp: pastebin.com/SztaHWT5
Cryptographic Proof of Existence: solution.zip
Solve Count At Time Of Writing: 224
Solves Per Month: 17.5
Reading Time: 9 minutes
Rendering Note:
There is a known issue with Android lacking a true monotype system font, which breaks many of the extended ASCII character set diagrams below. Please view this page on a Chrome or Firefox-based desktop browser to avoid rendering issues. Ideally on a Linux host.
Background
The following is a walkthrough for the first in the new series of Microcorruption challenges. The original CTF-turned-wargame was developed a decade ago by Matasano and centered around a deliberately vulnerable smart lock. The goal for each challenge was simple: write a software exploit to trigger an unlock.
NCC Group later acquired Matasano. They continued maintaining the wargame and added half a dozen new challenges on October 28th, 2022. The following walkthroughs document how to exploit them.
System Architecture
The emulated device runs on the MSP430 instruction set architecture. It uses a 16-bit little-endian processor and has 64 kilobytes of RAM. The official manual includes the details, but relevant functionality is summarized below.
Interface
Several separate windows control the debugger functionality.
A user input prompt like the following is the device's external communication interface.
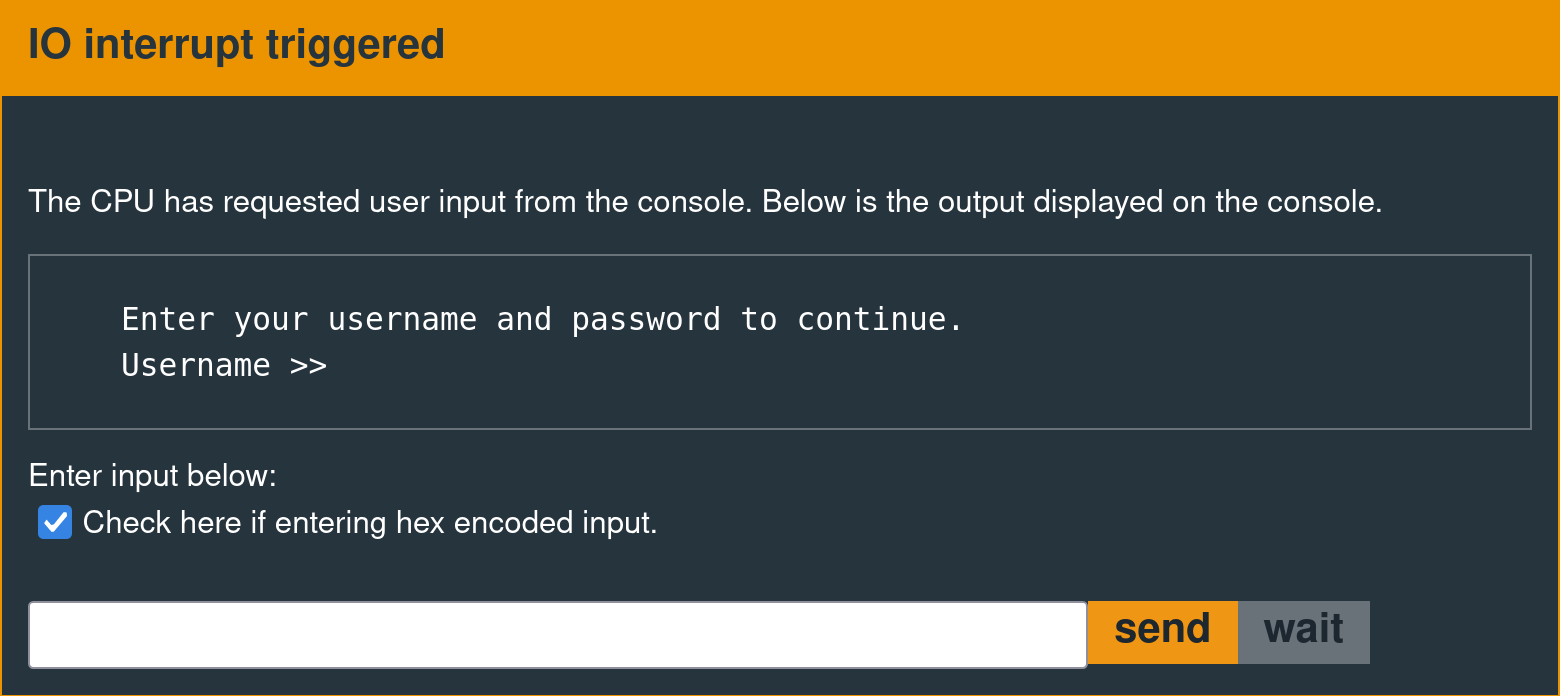
Exploit Development Objective
The equivalent of popping a shell on this system is calling interrupt 0x7F. On earlier challenges in the series, there is a dedicated function called unlock_door that does this.
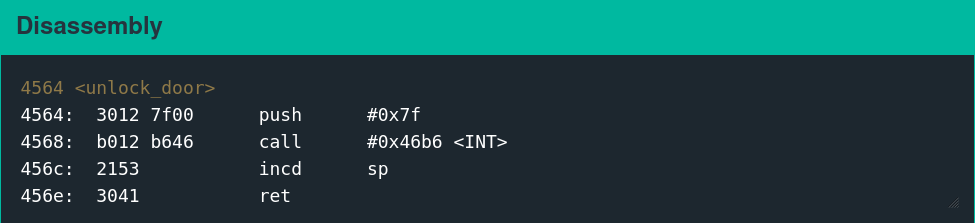
Executing the following shellcode is functionally equivalent to calling the unlock_door function.
Disassembly
3240 00ff mov #0xff00, sr
b012 1000 call #0x10
Assembly
324000ffb0121000The following message is displayed in the interface when the interrupt is called successfully.
High-Level Analysis
Sample Payload
The example payload provided in the challenge manual is as follows.
8000023041Sample Output
The following message is printed to the I/O console after the system executes the example payload.
Welcome to the test program loader.
Please enter debug payload.
Executing debug payload
Static Analysis
The first goal is to determine how the payload parsing logic works. The flow control graph for the main function is as follows:
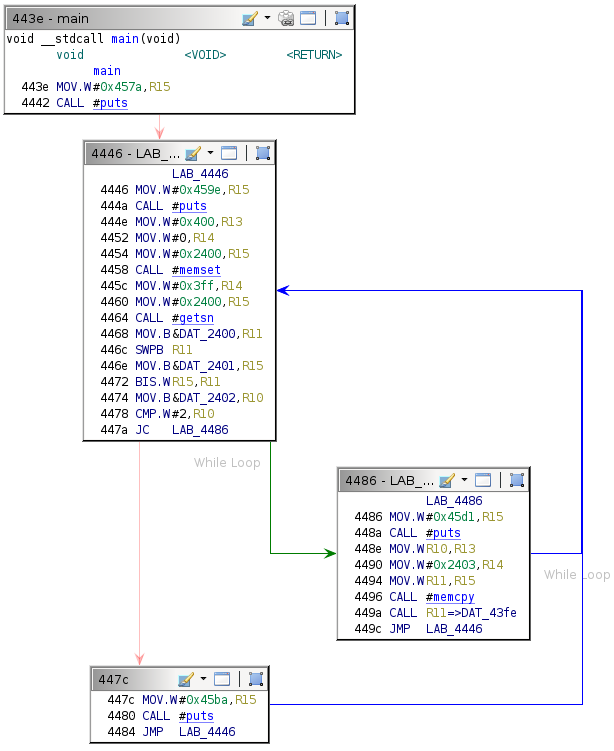
Observing the string printed by each conditional block allows the deduction of its purpose.
| String Address | String | Address of Conditional Block Containing Referencing Code |
|---|---|---|
| 457a | "Welcome to the test program loader." | 443e |
| 459e | "Please enter debug payload." | 4446 |
| 45ba | "Invalid payload length" | 447c |
| 45d1 | "Executing debug payload" | 4486 |
By way of example: "Please enter debug payload" is printed when execution reaches the conditional block labeled 4446 in the Ghidra graph.
Note that the third column in this table is the address of the conditional block where some code references the string, not the exact XREF or the address of the puts call.
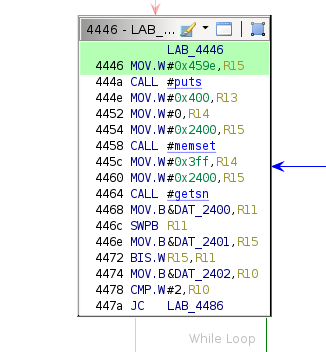
Input Buffer Address
Before commencing a more detailed analysis, it is necessary to note for future reference that the debug payload is read via a call to the getsn function and stored at address 0x2400.
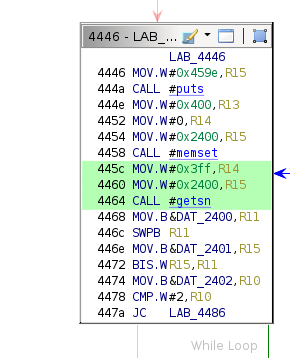
Control Flow Transfers
The payload executes soon after the I/O console prints the "Executing debug payload" string, so the conditional block beginning at address 0x4486 is worth scrutinizing. As expected, the puts call at 0x448a is followed several instructions later by an indirect register call.
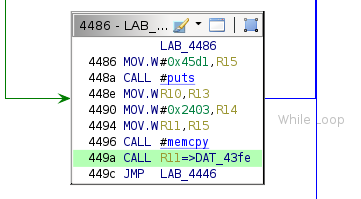
Register indirect calls are typically used when the address of the given function is not known at compile time (e.g., for just-in-time compilation), which means the debug payload may not have a constant load address. After parsing the payload, the firmware may load an externally supplied address into a register before branching to it. Hence, achieving successful arbitrary code execution first requires reaching that branch instruction.
Path to Code Execution
Whether the code reaches the aforementioned instruction is determined by the conditional jump highlighted in light green below:
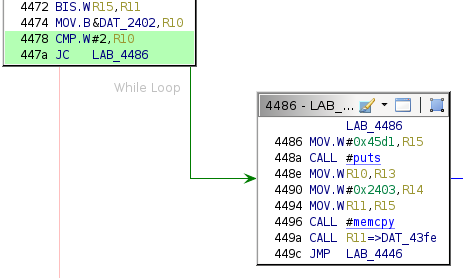
The code initially sets the value of R10 as follows.

The code sets the value of R10 to the byte at address 0x2402. This value is the third byte of the user-supplied debug payload:
8000023041The failing branch for this conditional prints the "Invalid payload length" string to the I/O console.
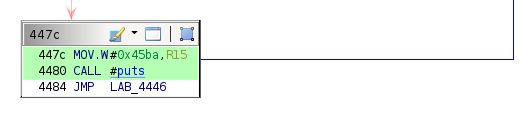
Logically, this byte must represent the payload length, which the check requires to be 0x2 or higher.
Redirecting Execution Flow
The next obvious question is where the register indirect call goes. The fact that the code performs a register-based call indicates that the target address is unknown at compile time, which suggests that the implementation reads it from an external source. The code sets the value of R11 via the following instructions:

Based on testing with the provided example payload, the register state after these instructions is as follows:
pc 447a sp 4400 sr 0003 cg 0000
r04 0000 r05 5a08 r06 0000 r07 0000
r08 0000 r09 0000 r10 0002 r11 8000
r12 2800 r13 0000 r14 03ff r15 0000
The value stored in R11 (after manipulations to correct the endianness) is the first two bytes of the debug payload. This word is a pointer to the location where execution will branch after the call.
Results
Load Address
Based on the fact that the value stored in R11 is interpreted as an address and called, the first two bytes of the payload appear to be the load address for the executable segment.
8000023041Executable Segment Size
The third byte is the executable segment size.
8000023041Executable Code
The last two bytes must be the executable segment contents—in this case, a single two-byte instruction.8000023041Disassembly
Disassembling these bytes produces a valid RET instruction.
3041 retThe executable section of the payload is copied to the load address via the memcpy function just before the call to R11. The assembly to do this is as follows:
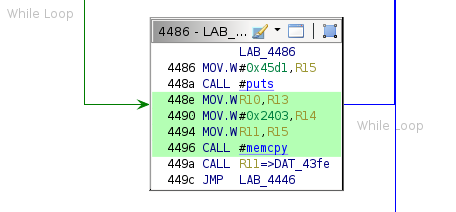
Even without knowing the calling convention for memcpy (which is likely the same as any other implementation), it is reasonable to assume that R10 is the number of bytes to copy (0x2), 0x2403 is the source location, and R11 (which contains 0x8000) is the destination address.
Examining the memory near address 0x8000 after the call to memcpy confirms this.
8000: 3041 0000 0000 0000 0000 0000 0000 0000 0A..............
8010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
8020: *
Payload format
| Load Address | Size (Bytes) | Executable code |
|---|---|---|
8000 |
02 |
3041 (RET) |
Final Exploit
Developing a working exploit payload is relatively straightforward: replace the single return instruction with the portable shellcode described earlier and increase the size of the executable segment to match.
| Load Address | Size (Bytes) | Executable code | Disassembly |
|---|---|---|---|
8000 |
08 |
3240 00ff b012 1000 |
mov #0xff00, sr |
800008324000ffb0121000The final payload increases the size field (highlighted above) from 0x2 to 0x8. Everything following that byte is shellcode.
Door Unlocked
The CPU completed in 19639 cycles.
Alternate Approaches
Jaime Lightfoot wrote a post that details the process of creating a working exploit with much less sophisticated analysis. The main difference is that Lightfoot glosses over understanding the size field—instead opting to insert a random byte that happens to work (0x90). The shellcode is also not portable because it wraps the INT function.
The payload is as follows:
90909030127f00b012a844The shellcode disassembly is below. The INT function is at address 0x44a8 in this particular firmware version.
3012 7f00 push #0x7f
b012 a844 call #0x44a8
Remediation
Every challenge in both this and the original series is pedagogically noteworthy for illustrating common flaws in developer logic. It is worthwhile to examine the underlying assumptions of the system architects before discussing technical fixes.
This system relies on the obscurity of the payload format to prevent an attacker from gaining arbitrary code execution. This "protection" is trivial to circumvent with superficial static analysis or runtime experimentation. While this is a relatively simple example, many commercial systems rely on precisely this type of "countermeasure" to protect intellectual property or prevent attackers from gaining code execution. There are at least two variants of this philosophy.
Fallacy #1: Compiled languages are "secure" against reverse engineering.
There seems to be an assumption (in some circles) that compiled languages are "secure" because compiled code is more time-consuming to read than source code. Developers looking to hinder reverse engineering efforts prefer languages like C or C++ over C# or Java. While it is possible to obfuscate the latter two by replacing function or variable names with random values, reading the source code and understanding high-level flow control is still a technically viable approach. These developers seem to assume that compiled languages make it harder for an attacker to understand flow control, possibly because they have never used Ghidra and are used to thinking of assembly as a flat, inscrutable list of alien machine instructions devoid of context.
They will argue that reverse engineering compiled code is time-consuming enough to deter most attackers, and the system is protected by it being too complicated to understand.
This argument is invalid for two reasons:
- Reading assembly is often not as difficult as many people might think—especially when dealing with resource-constrained embedded systems with small codebases. As Jaime Lightfoot's writeup demonstrates, it is possible to reverse engineer this firmware without Ghidra or any other tool. While there are debug symbols in this instance (i.e., function names), nothing prevents an attacker without access to debug symbols from guessing the purpose of functions and renaming them.
- Tools like Ghidra are usually passable at reconstructing the source code (or at least an assembly level flow control graph), eliminating the main theoretical advantage of compilation as a countermeasure.
To illustrate the second point, this is the decompilation of the main function.

This decompilation reconstructs the while loops more or less accurately, and the break statement on line 18 is syntactically correct. This decompilation is still somewhat convoluted because Ghidra has trouble determining the appropriate calling convention on the MSP430 ISA, but this is not typically an issue on ARM or x86. From a reverse engineering standpoint, the gap between compiled "secure" languages In this context, "secure language" means convoluted to reverse engineer rather than expensive to exploit. This uncommon use should not be confused with the more common jargon referring to memory safety. and obfuscated Java has closed significantly in the last two decades.
While it may slow them down slightly, the simple act of compilation does not prevent an attacker from understanding a given codebase. It is possible to introduce various types of code-level obfuscation (e.g., runtime encryption), but even this is not as effective as many developers might assume. Incidentally, the original challenge series required circumventing runtime encryption. For more details, see Jaime Lightfoot's write-up on Reykjavik. Code-level security through obscurity is not an effective reverse engineering countermeasure—this has been demonstrated time and time again by the failure of software-based anti-piracy solutions across the board.
Fallacy #2: Protocol obscurity will protect the system.
Once convinced that code-level obfuscation or compilation is ineffective, developers or technical managers will rationalize that security through obscurity only fails if the attackers can access the firmware. Some embedded systems rely on firmware update image encryption, hardware security, or physically restrictive deployment environments to prevent attackers from acquiring a compiled binary to analyze in the first place.
This tactic is still ineffective for multiple reasons. First, it is possible to intercept a sample payload and reverse engineer the protocol. For example: even without access to this firmware, it is possible to infer that the third byte is a size field by setting it to zero or one and observing the "Invalid payload length" status message at the I/O console. It is also possible to identify intelligible assembly by disassembling the payload at various offsets, which works well if the executable code segment is significantly larger. This approach provides a heuristic for narrowing down where to insert malicious code. Even without access to a firmware blob, black box protocol analysis against this system (and many others) would not require much effort.
Patching
Security through obscurity does not work. Instead, use sound cryptographic authentication. Implementing public key-based signature verification for the payload eliminates this class of problem.